
アクセスログは情報量が多いため、人力での調査は骨が折れる作業の一つだと思います。
そこで生成AIを使えば要約・分析に役立つのではと思い、bedrockを使う練習も兼ねてPoCを作ってみました。
構成概要
PoCの構成図・動作の流れは以下の通りです。
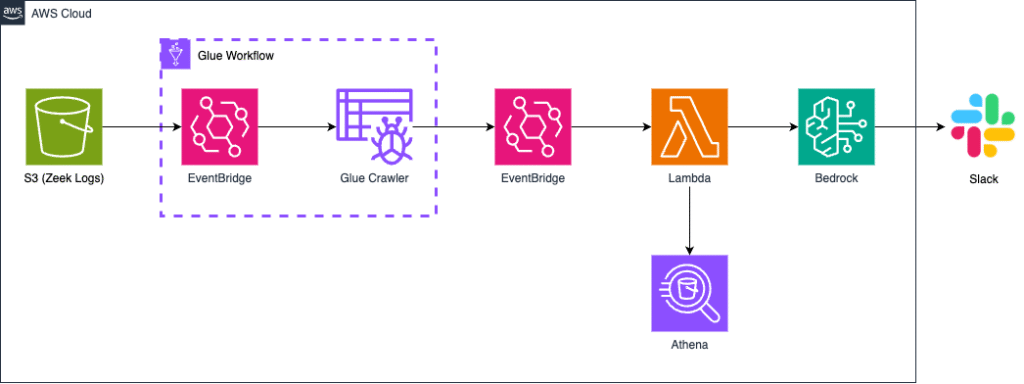
本構成のTerraformコード全文はこちらで公開しています。
https://github.com/tkodama1231/bedrock_AccessLog_Analysis_PoC
処理の流れ
- S3にアクセスログ(JSON形式)をアップロード
- EventBridgeでGlue Workflowを起動
- Glue Crawlerがログ構造を解析し、Athena用のテーブルを作成
- Workflowの完了イベントを再度EventBridgeで検知し、Lambdaを起動
- LambdaがAthenaにクエリを投げ、HTTPメソッド・ステータスコード・送信元IPを集計
- クエリ結果をBedrockに投げて、異常パターンや不審なIPを分析・要約
- 分析結果をSlackに通知
1. S3にアクセスログ(JSON形式)をアップロード
PoCで使用するサンプルログは、GitHubの brimdata/zed‑sample‑dataに公開されているZeekのネットワークログを使用します。
Zeekは、ネットワーク上の通信を詳細に記録するセキュリティツールです。
brimdata/zed‑sample‑dataにはzeekのサンプルログが公開されており、素材として使用できます。
今回は、json形式のzeekログである、zed-sample-data/zeek-json/http.json.gzをサンプルのログデータとして使用します。
2. EventBridgeでGlue Workflowを起動
今回のPoCでは、S3にログファイルがアップロードされると、それを契機として次の処理(Glue Workflowの起動)が実施される仕組みを作成してみました。
Amazon EventBridge を活用して、S3への新規オブジェクト作成イベントをトリガーとし、Glue Workflow を自動で起動する構成にしています。
EventBridgeから直接Glue Crawlerを起動することはできないため、Glue Workflow を間に挟む形にしています。
また、EventBridgeからGlue Workflowを起動するには、適切なIAMロールの付与が必要です。
後述のIAMロールポリシーの例を参考に、適切なロールを設定してください。
- EventBridge イベントパターン例
※<bucket name>にはS3バケット名をいれてください
{
"detail": {
"bucket": {
"name": [“<bucket name>"]
}
},
"detail-type": ["Object Created"],
"source": ["aws.s3"]
}- IAMロールポリシー例
※<glue workflow ARN>にはGlue WorkflowのARNをいれてください
{
"Statement": [
{
"Action": [
"glue:NotifyEvent"
],
"Effect": "Allow",
"Resource": [
"<glue workflow ARN>"
],
"Sid": "ActionsForResource"
}
],
"Version": "2012-10-17"
}3. Glue Crawlerがログ構造を解析し、Athena用のテーブルを作成
ログデータはJSON形式でS3に格納しますが、そのままではAthenaで効率的にクエリを投げることができません。そこで、Glue Crawler を使ってJSONファイルの構造を自動的に解析し、Athenaから参照可能なテーブルスキーマを作成します。
Crawlerの設定では、対象となるS3バケット等を指定し、結果を指定したGlue Databaseに出力します。
実際にGlue Crawlerによるスキーマ解析を行うことで作成されたテーブルは以下のようになりました。
このように、Glue Crawlerが自動で作成したテーブルを使用するため、Athena側でCREATE TABLEの処理を行う必要がなくなります。
[
{
"Name": "_path",
"Type": "string"
},
{
"Name": "_write_ts",
"Type": "string"
},
{
"Name": "ts",
"Type": "string"
},
{
"Name": "uid",
"Type": "string"
},
{
"Name": "id.orig_h",
"Type": "string"
},
{
"Name": "id.orig_p",
"Type": "int"
},
{
"Name": "id.resp_h",
"Type": "string"
},
{
"Name": "id.resp_p",
"Type": "int"
},
{
"Name": "trans_depth",
"Type": "int"
},
{
"Name": "method",
"Type": "string"
},
{
"Name": "host",
"Type": "string"
},
{
"Name": "uri",
"Type": "string"
},
{
"Name": "version",
"Type": "string"
},
{
"Name": "user_agent",
"Type": "string"
},
{
"Name": "request_body_len",
"Type": "int"
},
{
"Name": "response_body_len",
"Type": "int"
},
{
"Name": "status_code",
"Type": "int"
},
{
"Name": "status_msg",
"Type": "string"
},
{
"Name": "tags",
"Type": "array<string>"
},
{
"Name": "resp_fuids",
"Type": "array<string>"
},
{
"Name": "resp_mime_types",
"Type": "array<string>"
},
{
"Name": "referrer",
"Type": "string"
},
{
"Name": "orig_fuids",
"Type": "array<string>"
},
{
"Name": "orig_mime_types",
"Type": "array<string>"
},
{
"Name": "origin",
"Type": "string"
},
{
"Name": "proxied",
"Type": "array<string>"
}
]4. Workflowの完了イベントを再度EventBridgeで検知し、Lambdaを起動
Glue Crawler の処理が完了したら、次はそのイベントを検知して次のステップへ進める必要があります。
このPoCでは、Glue Crawler の完了イベントを Amazon EventBridge で検知し、それをトリガーとして Lambda を起動する構成を採用しました。
Workflow の完了を検知するためには、以下のような EventBridge のイベントパターンを使用します。
※<glue crawler name>にはGlue Crawlerの名前をいれてください
{
"detail": {
"crawlerName": ["<glue crawler name>"],
"state": ["Succeeded"]
},
"detail-type": ["Glue Crawler State Change"],
"source": ["aws.glue"]
}このパターンにマッチするイベントが発生すると、Athena クエリを実行する Lambda 関数が自動的に起動され、分析処理へと移行します。
なお、このEventBridgeにも専用の IAM ロールを付与する必要がある点に注意が必要です。
5. LambdaがAthenaにクエリを投げ、HTTPメソッド・ステータスコード・送信元IPを集計
5.〜7.ではAthenaを使ったログデータの加工、Bedrockへのリクエスト送信、slack通知の各種API連携を行うLambdaについての説明です。
Lambdaで使用しているソースコードはこちら。
import boto3
import json
import os
import time
import requests
athena = boto3.client("athena")
bedrock = boto3.client("bedrock-runtime")
ATHENA_DB = os.environ.get("ATHENA_DB")
ATHENA_TABLE = os.environ.get("ATHENA_TABLE")
ATHENA_OUTPUT = os.environ.get("ATHENA_OUTPUT")
SLACK_WEBHOOK_URL = os.environ.get("SLACK_WEBHOOK_URL")
def run_athena_query(query):
response = athena.start_query_execution(
QueryString=query,
QueryExecutionContext={"Database": ATHENA_DB},
ResultConfiguration={"OutputLocation": ATHENA_OUTPUT},
)
query_execution_id = response["QueryExecutionId"]
while True:
status = athena.get_query_execution(QueryExecutionId=query_execution_id)
state = status["QueryExecution"]["Status"]["State"]
if state in ["SUCCEEDED", "FAILED", "CANCELLED"]:
break
time.sleep(1)
if state != "SUCCEEDED":
Exception(f"Athena query failed with state: {state}")
result = athena.get_query_results(QueryExecutionId=query_execution_id)
rows = result["ResultSet"]["Rows"]
header = [col["VarCharValue"] for col in rows[0]["Data"]]
data = [
dict(zip(header, [col.get("VarCharValue", "") for col in row["Data"]]))
for row in rows[1:]
]
return data
def invoke_bedrock(prompt, max_retries=3):
payload = {
"messages": [{"role": "user", "content": [{"text": prompt}]}],
"inferenceConfig": {"temperature": 0.3, "topP": 0.9, "maxTokens": 1000}
}
for attempt in range(max_retries):
try:
response = bedrock.invoke_model(
modelId="amazon.nova-lite-v1:0",
contentType="application/json",
accept="application/json",
body=json.dumps(payload)
)
result = json.loads(response["body"].read().decode("utf-8"))
message = result["output"]["message"]["content"][0]["text"]
if "blocked by our content filters" in message.lower():
print(f"[WARN] Content blocked (attempt {attempt+1}): {message}")
time.sleep(1)
continue
return message
except Exception as e:
print(f"[WARN] Bedrock failed (attempt {attempt+1}): {e}")
time.sleep(1)
raise Exception("Bedrock failed after retries")
def lambda_handler(event, context):
query = f"""
SELECT
"id.orig_h" AS source_ip,
method,
status_code,
COUNT(*) AS count,
'anomaly_method' AS reason
FROM {ATHENA_TABLE}
WHERE method NOT IN ('GET', 'POST')
GROUP BY "id.orig_h", method, status_code
UNION ALL
SELECT
"id.orig_h" AS source_ip,
method,
status_code,
COUNT(*) AS count,
'mass_access' AS reason
FROM {ATHENA_TABLE}
GROUP BY "id.orig_h", method, status_code
HAVING COUNT(*) > 100
"""
records = run_athena_query(query)
print("=== records ===")
print(records)
prompt_lines = [
"以下はシステム動作の分析支援を目的とした出力で、HTTPメソッド、ステータスコード、送信元IP別に集計したアクセス件数の一覧です。\n"
"このデータをもとに、セキュリティ的に不審なアクセスパターンがないかを分析してください。\n"
"・異常なアクセス傾向(例:不審なメソッド、エラーステータスの多発)\n"
"・全体と比較して突出した件数のIPアドレスの存在\n"
"・その他、不自然な挙動\n"
"これらの観点で簡潔に要点をまとめてください。\n"
"```\n["
]
for record in records:
status_code = (
int(record["status_code"])
if record["status_code"].isdigit()
else None
)
prompt_lines.append(json.dumps({
"method": record["method"],
"status_code": status_code,
"source_ip": record["source_ip"],
"count": int(record["count"])
}) + ",")
prompt_lines.append("]\n```")
prompt = "\n".join(prompt_lines)
summary = invoke_bedrock(prompt)
if SLACK_WEBHOOK_URL:
requests.post(SLACK_WEBHOOK_URL, json={"text": summary})
else:
print("Slack Webhook URL is not set.")
return {"statusCode": 200, "body": "完了"}Glue Crawler によって作成された Athena テーブルに対して、Lambda 関数が SQL クエリを投げ、HTTPメソッド、ステータスコード、送信元IPアドレスの3項目の集計を行います。
本来であれば、ログの全件をBedrockに渡して解析させることも可能ですが、サンプルとして使用しているZeekのログは1ファイルあたりの情報量が非常に多く、直接送信すると生成AI側での処理が重くなってしまいます。
そのため、Bedrockに渡す前段階として、Lambda上でアクセス傾向に関する特徴的な要素をあらかじめ抽出し、分析対象を絞り込む構成にしました。
高性能のAIモデルを使用したり、ログの分割処理などによって改善の余地があるかもしれません。
Lambda関数では、Athenaのstart_query_executionを使用して、クエリを実行します。
このクエリでは、Glue Crawler によって自動生成されたテーブルスキーマをそのまま利用できるため、SQLの定義も簡素化できます。
実際に実行しているクエリは以下の通りです。
※{ATHENA_TABLE}にはクエリ実行対象のテーブル名が入ります
SELECT
"id.orig_h" AS source_ip,
method,
status_code,
COUNT(*) AS count,
'anomaly_method' AS reason
FROM {ATHENA_TABLE}
WHERE method NOT IN ('GET', 'POST')
GROUP BY "id.orig_h", method, status_code
UNION ALL
SELECT
"id.orig_h" AS source_ip,
method,
status_code,
COUNT(*) AS count,
'mass_access' AS reason
FROM {ATHENA_TABLE}
GROUP BY "id.orig_h", method, status_code
HAVING COUNT(*) > 100また、Athenaへのクエリ実行や後述するBedrockへのリクエスト送信など、Lambda関数が複数のAWSサービスと連携するためには、適切なIAMポリシーの設定が必要です。
このPoCでは以下のような操作を行うため、それぞれに対応した権限をLambdaに付与しています。
- S3関連権限
- ログデータの取得(s3:GetObject, s3:ListBucket)
- Athenaクエリ結果の取得・保存(s3:GetObject, s3:PutObject, s3:GetBucketLocation)
- Athena権限
- クエリの実行と結果の取得(athena:StartQueryExecution, athena:GetQueryExecution, athena:GetQueryResults)
- Glue権限
- データベース・テーブル情報の取得(glue:GetDatabase, glue:GetTable, glue:GetTables)
- Bedrock権限
- Foundation Model(FM)へのリクエスト実行(bedrock:InvokeModel)
- CloudWatch Logs権限
- ログ出力のための基本操作(logs:CreateLogGroup, logs:CreateLogStream, logs:PutLogEvents)
これらの権限を正しく設定しないと、Lambdaの実行時にエラーが発生する可能性があります。
PoC実装時に実際に使用したIAMポリシーの全文は以下の通りです。
※ <>括弧の部分は適宜置き換えてください。
{
"Version": "2012-10-17",
"Statement": [
{
"Action": [
"s3:GetObject",
"s3:ListBucket"
],
"Effect": "Allow",
"Resource": [
"arn:aws:s3:::<Zeekログ格納用S3バケット名>",
"arn:aws:s3:::<Zeekログ格納用S3バケット名>/*"
]
},
{
"Action": [
"s3:PutObject",
"s3:ListBucket",
"s3:GetObject",
"s3:GetBucketLocation"
],
"Effect": "Allow",
"Resource": [
"arn:aws:s3:::<Athenaクエリ出力用S3バケット名>/*",
"arn:aws:s3:::<Athenaクエリ出力用S3バケット名>"
]
},
{
"Action": [
"bedrock:InvokeModel"
],
"Effect": "Allow",
"Resource": "*"
},
{
"Action": [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents"
],
"Effect": "Allow",
"Resource": "arn:aws:logs:*:*:*"
},
{
"Action": [
"athena:StartQueryExecution",
"athena:GetQueryExecution",
"athena:GetQueryResults"
],
"Effect": "Allow",
"Resource": "*"
},
{
"Action": [
"glue:GetDatabase",
"glue:GetTable",
"glue:GetTables"
],
"Effect": "Allow",
"Resource": [
"arn:aws:glue:ap-northeast-1:<アカウントID>:catalog",
"arn:aws:glue:ap-northeast-1:<アカウントID>:database/zeek-logs-db",
"arn:aws:glue:ap-northeast-1:<アカウントID>:table/zeek-logs-db/*"
]
}
]
}6. クエリ結果をBedrockに投げて、異常パターンや不審なIPを分析・要約
集計したアクセスログの要約・分析には、Amazon Bedrock を活用しています。
事前準備
Bedrockでは、テキスト、画像、コード生成など、それぞれ異なる分野に特化したFoundation Model(FM)が多数用意されています。
本PoCでは、アクセスログのテキスト解析を目的としていたため、テキスト応答に特化した「amazon.nova-lite-v1:0」を採用しました。
このモデルは日本語の応答に対応しつつ、コストも比較的安価で、生成AIを用いた分析の入口として最適でした。
Bedrockの利用にあたっては、事前に「model access」のリクエストを行い、利用したいモデルに対してアクセス権を付与しておく必要があります。

bedrockへのリクエスト
以下はLambda関数で使用している、bedrockへリクエストを送信する処理の抜粋です。
def invoke_bedrock(prompt, max_retries=3):
payload = {
"messages": [{"role": "user", "content": [{"text": prompt}]}],
"inferenceConfig": {"temperature": 0.3, "topP": 0.9, "maxTokens": 1000}
}
for attempt in range(max_retries):
try:
response = bedrock.invoke_model(
modelId="amazon.nova-lite-v1:0",
contentType="application/json",
accept="application/json",
body=json.dumps(payload)
)
result = json.loads(response["body"].read().decode("utf-8"))
message = result["output"]["message"]["content"][0]["text"]
if "blocked by our content filters" in message.lower():
print(f"[WARN] Content blocked (attempt {attempt+1}): {message}")
time.sleep(1)
continue
return message
except Exception as e:
print(f"[WARN] Bedrock failed (attempt {attempt+1}): {e}")
time.sleep(1)
raise Exception("Bedrock failed after retries")Lambdaからモデルを呼び出す際は、modelId・Content-Type・Accept ヘッダーなどを正しく指定し、適切なリクエストボディの構造も求められます。
リクエストボディには messages というフィールドを含め、各メッセージに role(通常は”user”)と content(送信する内容)を明示的に記述します。
さらに、生成AIの応答の特製を制御するinferenceConfig も指定できます。制御可能なパラメータには次のようなものがあります。
- temperature:生成のランダム性を制御するパラメータ。値が低いほど、より決まりきった、安定的な出力になります。
- topP:生成される語彙の多様性を調整する指標。値が高いと、より幅広い語彙からの選択が行われます。
- maxTokens:出力されるトークンの最大数。生成文の長さの上限を定めます。
これらのパラメータを調整することで、安定した応答や、適度に要約された結果が得られるようにできます。
プロンプト設計
プロンプトの設計も重要なポイントです。Bedrockでは、攻撃手法やセキュリティリスクに関するセンシティブなプロンプトを送ると、blocked by our content filters のようなエラーが返されることがあります。
これを回避するために、プロンプト内に 「システム動作の分析支援を目的としている」 といった利用目的の健全性を明示する記述を含めることで応答確率が向上しました。
実際に使用したプロンプトはこちらです。
以下はシステム動作の分析支援を目的とした出力で、HTTPメソッド、ステータスコード、送信元IP別に集計したアクセス件数の一覧です。
このデータをもとに、セキュリティ的に不審なアクセスパターンがないかを分析してください。
・異常なアクセス傾向(例:不審なメソッド、エラーステータスの多発)
・全体と比較して突出した件数のIPアドレスの存在
・その他、不自然な挙動
これらの観点で簡潔に要点をまとめてください。
[
<ログの集計結果>
]このプロンプトは固定ではなく、Bedrockの動作特性やモデルのアップデートに合わせて柔軟に見直していくことが重要です。
なお、今回の構成では、生成AIに送るデータをLambda側で事前にフィルタ・要約していますが、将来的に高性能なFMを活用したり、ログを段階的に分割して送信するような構成にすることで、より網羅的な分析が可能になるかもしれません。
7. 分析結果をSlackに通知
Bedrockによって生成された分析結果は、SlackのWebhook URLを通じてslackのチャネルに通知されます。
Lambda関数内でHTTPリクエストを送信するだけのシンプルな処理としています。
requests.post(SLACK_WEBHOOK_URL, json={"text": summary})動作確認
実際に、サンプルのログファイルをS3バケットに格納すると、どのような通知がslackに届くか確認してみます。
S3にオブジェクトが生成されると自動的にログデータの前述した2.〜7.の処理が走るはずです。
zed-sample-data/zeek-json/http.json.gz のサンプルログファイルを解凍し、s3にアップロードします。
% aws s3 cp ./zed-sample-data/zeek-json/http.json s3://<s3バケット名>すると数分後にslackに以下のようなテキストが通知されました。

セキュリティログが要約された内容が届きました。
プロンプトに従って、異常なアクセス傾向・突出した件数のIPアドレス・その他不自然な挙動の観点でまとめてくれています。
ですがよく見ると、出力の末尾が切れてしまっています。
もう一度実行すると、不自然に出力が途切れることなくメッセージが届きました。
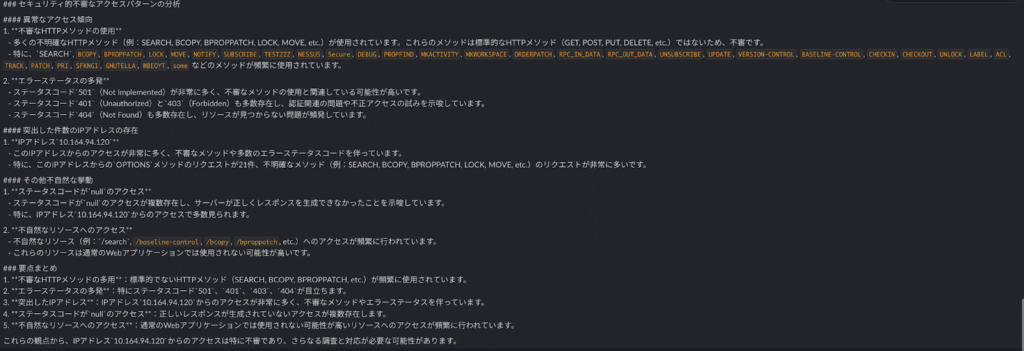
このあたりはmaxTokenなどのパラメータや、プロンプトを工夫するなどの改善の余地があるかもしれません。
まとめ
本PoCでは、S3にアップロードされたアクセスログをトリガーとして、Glue Crawler による構造解析、Athenaによる集計、Bedrockによる生成AI分析、そしてSlackへの通知までを一連のフローで自動化しました。
手作業では難しい大量ログの可視化・要約を、生成AIを組み込むことで効率化できることを確認できました。
アクセスログなどの大量のデータを分析する場合、AIへの負荷を抑える工夫やモデルの選定が鍵となりそうです。
より高性能なモデルや分割処理などを導入することで、さらに広範囲な分析も可能になると考えられます。

コメント