
最近、業務の中でStepFunctionsを使用してサーバレスアプリケーションを作る機会がありました。
その中で、「StepFunctionsってこういうことができるリソースだったのか!」とか、「StepFunctionsってこういう機能があるのか!」といった発見がありましたのでまとめます!
StepFunctionsとは?
まずはAWSより引用
AWS Step Functions は、分散アプリケーションの構築、プロセスの自動化、マイクロサービスのオーケストレーション、データおよび機械学習 (ML) パイプラインの作成に役立つビジュアルワークフローサービスです。
https://docs.aws.amazon.com/ja_jp/step-functions/latest/dg/welcome.html
自分なりの解釈を交えて簡単に言い換えると、複数のLambda関数などで構成されるアプリケーションがあった時、
「どういう順番でLambda関数を動作させるのか」や「Lambda関数の実行条件に関する条件分岐」といった制御を含む分散アプリケーションのワークフローを視覚的に実装できるサービスとなります。
ここで作成したワークフローにあたるリソースは「ステートマシン」というリソースとしてAWS上に作成されます。
StepFunctionsで定義されるステートマシンを構成する要素のことを「状態」と呼びます。
状態には様々な種類があります。以下、AWSからの引用です。
https://docs.aws.amazon.com/ja_jp/step-functions/latest/dg/concepts-states.html
- ステートマシンで何らかの作業をする (Task 状態)。
- 実行の選択肢間で選択する (選択状態)
- 失敗または成功で実行を停止する (失敗または成功状態)
- 入力を出力に渡す、または一部の固定データをワークフローに挿入する (パス状態)
- 一定時間または指定された日時まで遅延を設ける (待機状態)
- 実行の並列ブランチを開始する (並行状態)
- ステップを動的に反復する (マップ状態)
Task状態はLambda関数などStepFunctionsと統合できるAWSリソースで何らかの操作を実行します。「Lambda関数を実行する」、「ECSタスクを実行する」などが該当します。
選択状態はいわゆるif分岐であり、「条件分岐」の制御をワークフローに組み込むことができます。
失敗または成功状態は、ワークフローを強制的に「成功」または「失敗」の状態にして実行を停止します。
パス状態は、入力データの加工や追加を実施します。データを上から下に流すだけの状態ですが、ここでできるデータの加工が割と面白かったので、パス状態で実行できる処理について後述する章では詳しく説明したいと思います!
待機状態は文字通り、指定した時間ワークフローを停止して待機する制御です。AWSのリソースはAPIを実行してから状態が反映されるまで時間がかかるケースが多いので、何かと使い勝手が良いと思います。
並列状態はタスクの並列処理を実行する制御です。「複数タスクが完了してから、次のタスクに進ませたい」といった状況で便利です。
マップ状態は入力値を配列で定義し、配列の要素ごとに並列処理を実行する制御です。
並列状態とマップ状態の違いについては、こちらの記事でわかりやすく解説されておりました。
以上のようなTask状態とワークフローを定義する様々な状態を組み合わせることでワークフローを構築するんですね!
本記事では特に、「パス状態でできること」について学んだことを残していきたいと思います!
Pass状態を作成してみる
Pass状態では、平たくいうと「簡単なデータの加工ができる状態」です。
AWSのコンソール画面でステートマシンを作成し、Pass状態を作成してみました。
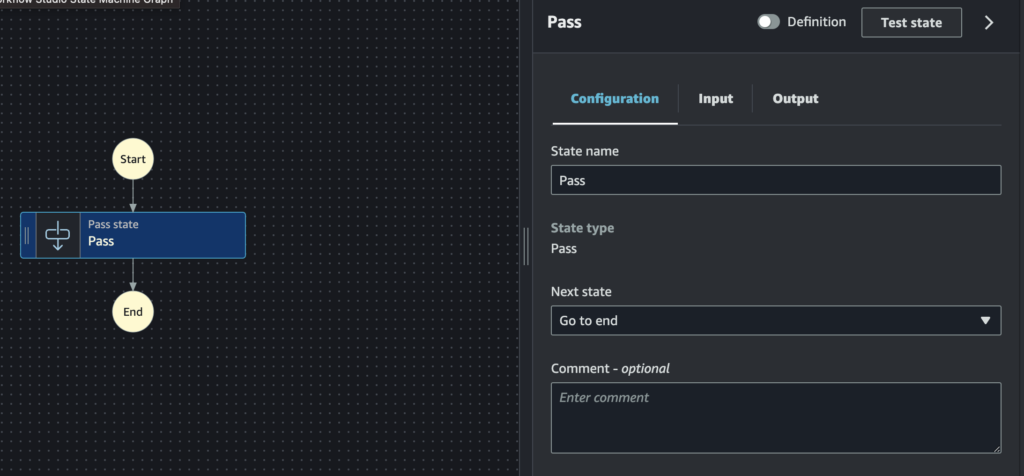
画面右側のタブから分かる通り、”Input”(入力),”Output”(出力)の設定があります。
つまり、「Pass状態の入口と出口でデータを加工することができる」ということを意味しています。
入力
入力側で実行できるデータ変換は次の2つです。
- InputPathで入力をフィルタリング
- Parametersを使用して入力を変換
初めてstepfunctionsを使用した時の個人的な感想ですが、これらの設定項目はじめはどのような設定なのか意味がわかりませんでした笑
以下に自分なりの理解をまとめてみたいと思います。
InputPathで入力をフィルタリング
最もシンプルなフィルタで、「入力データの内、フィルタで指定した部分のみをパス状態に取り込みます」という設定項目です。
例えば、次のようなデータがパス状態に入力されたとします。
{
"comment": "Example for InputPath.",
"dataset1": {
"val1": 1,
"val2": 2,
"val3": 3
},
"dataset2": {
"val1": "a",
"val2": "b",
"val3": "c"
}
}「InputPathで入力をフィルタリング」に「$.dataset2」を指定します。
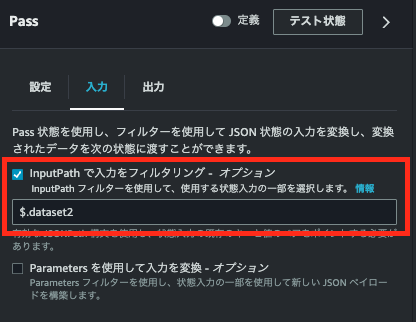
結果として、Pass状態に入力として与えられるのは次の部分となります。
(コンソール画面、「テスト状態」ボタンから確認することができます。)
"dataset2": {
"val1": "a",
"val2": "b",
"val3": "c"
}元々のデータから、dataset2に相当するデータだけが抽出されたことがわかります。
Parametersを使用して入力を変換
この設定では入力データを新しく作成し直すことができる設定です。
全く新しいデータを新しく作成することもできますが、$で始まる文字列を使用することで、元々の入力データからデータを引用することも可能です。
例えば、次のデータがパス状態に入力されたとします。
{
"comment": "Example for InputPath.",
"dataset1": {
"val1": 1,
"val2": 2,
"val3": 3
},
"dataset2": {
"val1": "a",
"val2": "b",
"val3": "c"
}
}「Parametersを使用して入力を変換」を以下のように指定します。
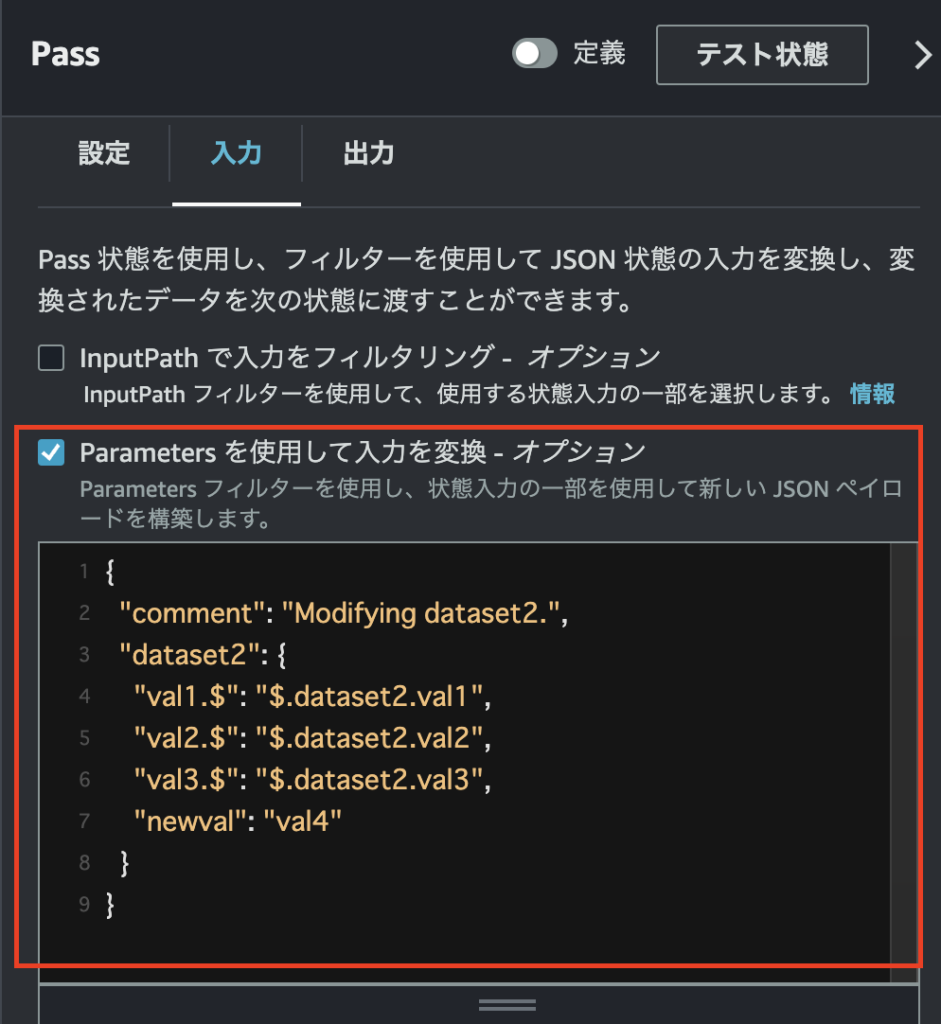
この設定では”comment”キーの値を変更し、dataset2の”val1″,”val2″,”val3″を入力データから引用、さらに”newval”というキーをdataset2に追加しています。
元々の入力データから値を引用する場合は、引用対象のデータを$.<オブジェクト名>.<フィールド名>のような形で記述します。
これはStepFunctionsの記述で使用するAmazon States Languageのパス(Path)という概念(名前が同じですがパス(Pass)状態とは別物です。紛らわしい…)です。詳しくは公式ドキュメントを参照ください。
入力データからの引用を用いる場合は、変換後のパラメータのキーの末尾にも.$をつける必要があることにご注意ください。
parametersによる入力データ変換を行なった結果は次のようになります。
{
"comment": "Modifying dataset2.",
"dataset2": {
"newval": "val4",
"val3": "c",
"val2": "b",
"val1": "a"
}
}新しいデータの追加や元々の入力データからの引用が行われていることがわかります。
出力
出力側で実行できるデータ変換は次の2つです。
- ResultPath を使用して元の入力を出力に追加
- OutputPath で出力をフィルタリング
出力側もどのような変更が行われるか直感的に分かりづらいと思います。
しかし、使いこなせるとサーバレスアプリケーションの実装の幅が広がる便利な機能です。
一つ一つ見ていきましょう!
ResultPath を使用して元の入力を出力に追加
これは任意のキー・バリューペアを入力データに付加することができる機能です。例えば、次のようなデータがパス状態に入力されたとします。
{
"comment": "Example for InputPath.",
"dataset1": {
"val1": 1,
"val2": 2,
"val3": 3
},
"dataset2": {
"val1": "a",
"val2": "b",
"val3": "c"
}
}この入力に新しいデータセットdataset3を追加してみます。
"dataset3": {
"val1": "あ",
"val2": "い",
"val3": "う"
}コンソール画面では次のように指定します。
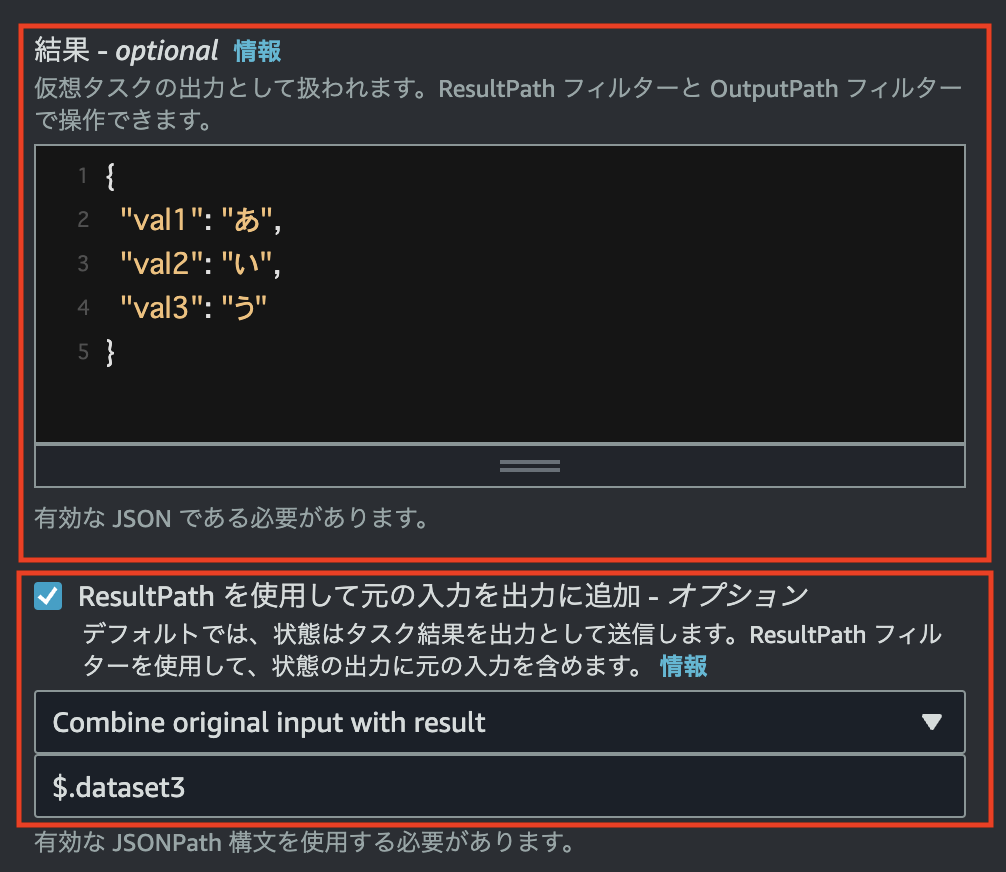
“結果”部分に追加したいデータを定義し、そのデータに指定するキーを”ResultPathを使用して元の入力を出力に追加”に定義します。
出力結果は次のようになります。
{
"comment": "Example for InputPath.",
"dataset1": {
"val1": 1,
"val2": 2,
"val3": 3
},
"dataset2": {
"val1": "a",
"val2": "b",
"val3": "c"
},
"dataset3": {
"val1": "あ",
"val2": "い",
"val3": "う"
}
}また、追加したいデータに付加するキーを元々の入力データに存在するdataset2とした場合は、出力が次のようになります。
{
"comment": "Example for InputPath.",
"dataset1": {
"val1": 1,
"val2": 2,
"val3": 3
},
"dataset2": {
"val1": "あ",
"val2": "い",
"val3": "う"
}
}このように、データを追加するのではなく、データを書き換える処理もResultPathの設定により行うことができます。
ResultPathを使用した出力データの追加や変換は使い勝手が良く、個人的にはオススメしたい機能になります!
複数のマイクロサービスをStepFunctionsを使って連携する時など、StepFunctions側の処理で(サービスそのもののコードをいじることなく)ちょっとしたデータの加工や追加を簡単に行うことができます。
OutputPathで入力をフィルタリング
機能としてはInputPathでの入力フィルタと似ています。
「出力データの中から、フィルタで指定した部分のみをパス状態の出力とする」という設定項目です。
例えば、次のようなデータがパス状態に入力されたとします。
{
"comment": "Example for InputPath.",
"dataset1": {
"val1": 1,
"val2": 2,
"val3": 3
},
"dataset2": {
"val1": "a",
"val2": "b",
"val3": "c"
}
}「OutputPathで出力をフィルタリング」に「$.dataset2」を指定します。

結果として、Pass状態にから出力されるのは次の部分となります。
"dataset2": {
"val1": "a",
"val2": "b",
"val3": "c"
}InputPathでのフィルタはパス状態の入力側でフィルタを行う一方、OutputPathでのフィルタはパス状態の出力側でフィルタを行う違いがありますが、機能的には大きな違いが無いと思われます。
入力側、出力側の2箇所でフィルタ設定をした場合は、「入力側でのフィルタ処理を先に実行→出力側でのフィルタ処理実行」の流れになる点が留意点となります。
まとめ
- Pass状態を使って簡単なJSONデータの加工ができる
- Pass状態の入力・出力の2箇所でデータ変換ができる
- JSONデータのフィルタリングやデータの追加・変換ができる
Pass状態でのデータ変換は他の状態でも同様に使用できる場合があります。
よって、Pass状態をマスターすればStepFunctionsのデータ加工はマスターしたも同然だと思いますし、この機能本当に痒い所に手が届く!!
参考にしていただければ幸いです!

コメント